
面向去中心化Web 3.0应用的联邦分析赋能的频繁模式挖掘
作者:上海交通大学的王子博、朱逸飞、香港理工大学的王丹和休斯顿大学的朱晗
研究背景:
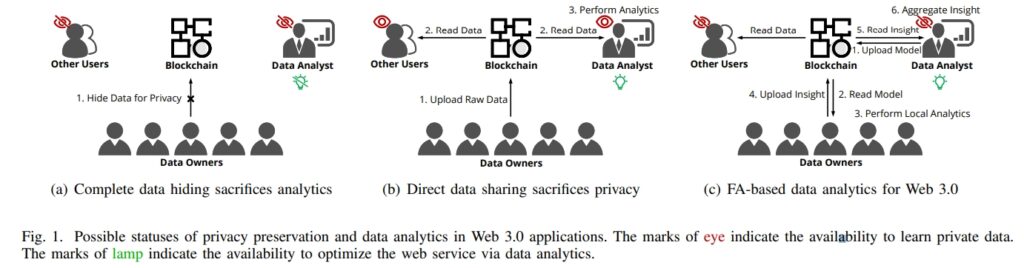
Web 3.0旨在去中心化现有网络服务,实现透明、激励和隐私保护等特性,但当前基于区块链基础设施的Web 3.0应用仍无法以可扩展和隐私保护的方式支持复杂的数据分析任务。
联邦分析(FA)是一种隐私保护数据分析范式,其去中心化性质与Web 3.0应用的需求自然匹配。
关键技术:
分布式差分隐私(DDP):通过分布式噪声生成和安全聚合来实现本地隐私保护,同时获得与中央差分隐私(CDP)相当的数据效用。
候选填充(candidate padding)和数据所有者复用(data owner reusing)策略:进一步减少参与的数据所有者数量。
实验结论:
在三个代表性的Web 3.0场景中进行实验,FedWeb相比其他基准方法,F1分数至少提高了25.3%,参与的数据所有者减少了81.1% – 98.4%。
数据所有者复用策略在节省参与数据所有者方面效果更好,但需要数据所有者等待多个轮次;候选填充策略执行效率更高,但在节省数据所有者方面效果稍逊。
参数ϵ和K对FedWeb的性能有重要影响,较大的ϵ/K会带来更好的数据效用,较大的K可减少数据所有者的使用。
贡献总结:
将FA引入当前Web 3.0生态系统,使数据分析能够在不暴露敏感原始数据的情况下进行。
设计了FedWeb用于Web 3.0服务中的隐私保护频繁模式挖掘,采用DDP私有化方案并设计了两种策略来节省响应预算,克服了现有Web 3.0服务中的规模限制。
严格证明了候选模式过滤方案的正确性,为FedWeb的频繁模式挖掘结果提供了理论保证。
论文pdf 下载链接:https://arxiv.org/pdf/2402.09736